
Traditional search technology matches results based only on the keywords and synonyms in a query. But in the law, where language is highly nuanced and arguments are often based on concepts and analogies, keyword searches fall woefully short. Casetext’s Parallel Search changes the game by taking a natural language sentence from the user and returning passages from the law that mean the same thing even when they have no words in common. Try for yourself.
For example, an attorney can enter a proposition of law such as “The right to protest is fundamental to American democracy,” and Parallel Search returns the following in federal circuit courts:
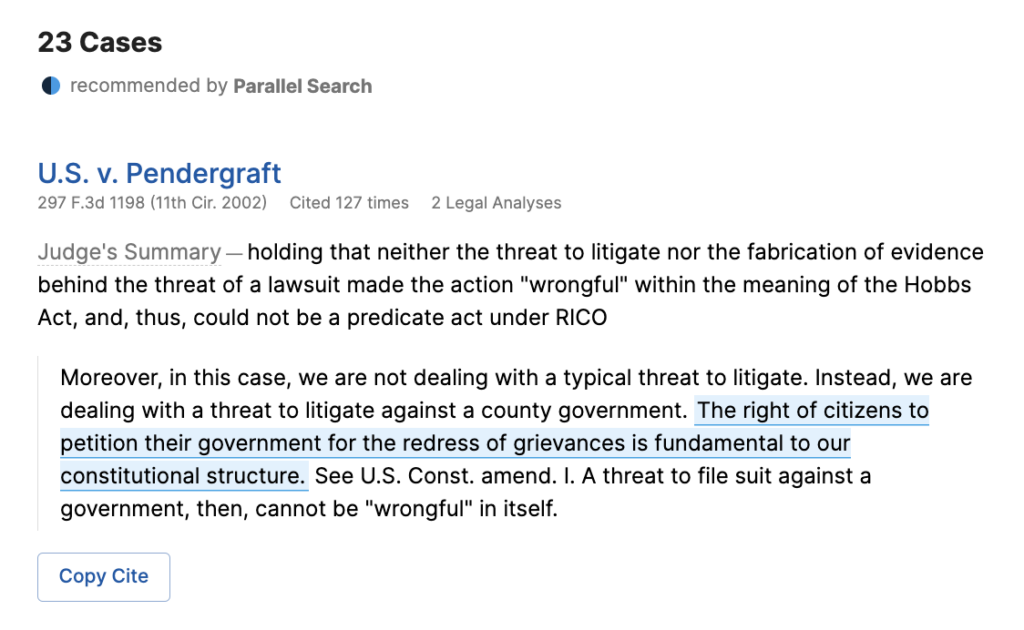
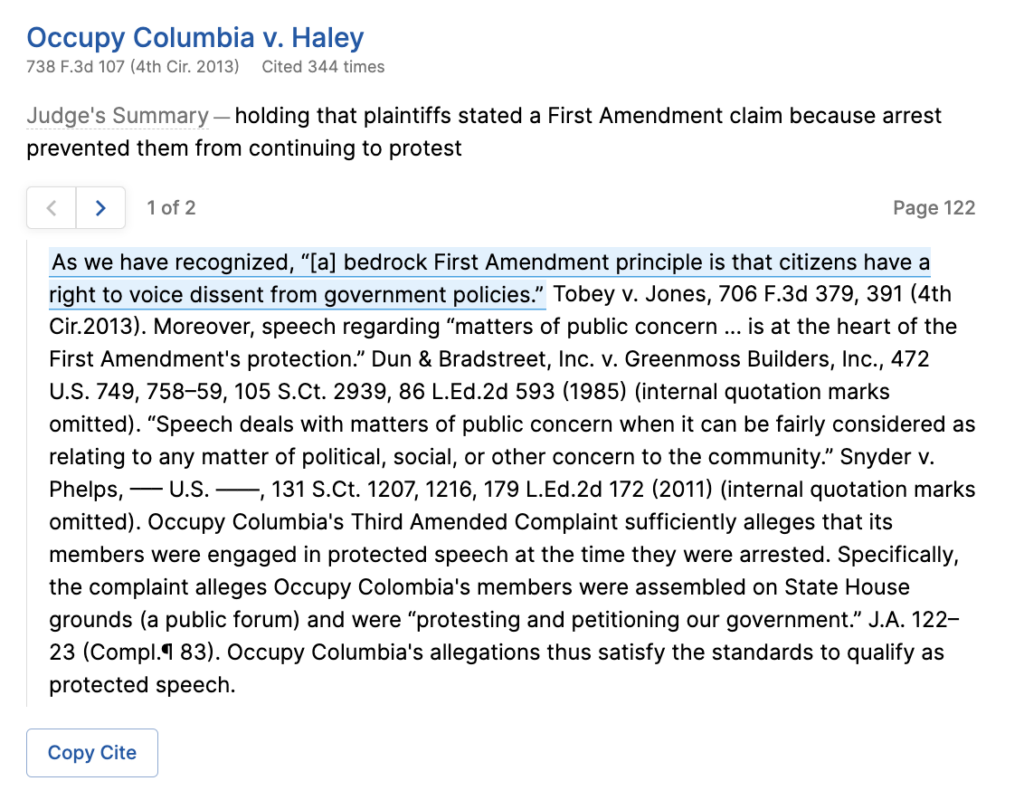
Although the top two results are statements written by judges perfectly supporting the proposition, search techniques that rely on keyword matches would not be able to locate these results. The first result shares only two important words with the query, “fundamental” and “right,” which appear in the same sentence in 190,000 cases. For the second result, which only shares the word “right” with the query, word matching is even less sufficient; the word “right” appears in over four million cases.
So, how was Parallel Search able to do it? Parallel Search uses advanced machine learning techniques to extract concepts from sentences, and find matches based on concepts, rather than keywords. In this article, I will explain, at a high level, how that machine learning works.
The fundamental building block of Parallel Search is a type of artificial neural network called the transformer. An artificial neural network is a machine learning technique loosely inspired by the structure of neurons in the brain. Neural networks are structured as many layers of pattern recognizers stacked on top of each other. The first layer takes in the input data, finds simple patterns in it, and passes information about those patterns on to the next layer. Each successive layer is able to recognize increasingly complex patterns.
These are patterns recognized by successive layers in a computer vision neural network (which we’re using as an example here because the patterns they recognize are much easier to visualize):

As you can see, the early layers on the left hand side recognize simple patterns, like variously angled lines, and color gradients. As we move through the layers to the right, the patterns are created by combining the patterns from the layer before into more complex shapes. At the rightmost layer, you can see quite complex shapes emerging, like wheels, and honeycombs.
The patterns that neural networks recognize are not pre-programmed by human programmers. Instead, they are “learned” by adjusting the weights of connections between layers in the network. This is done by running large numbers of examples of inputs and the desired outputs through the network and adjusting the weights of the connections a little bit at a time to make the output of the network progressively closer to the desired output.
Transformers are a type of neural network that is good at doing pattern recognition on text instead of images. For more detail on transformers, you can read an earlier post about them.
Casetext is one of the first companies in the world to apply neural transformers to the problem of natural language semantic search. Our system involves a neural transformer model that was pre-trained on the entire body of US judicial opinions.
The naive way to try to do semantic search with neural transformers is to feed each possible result sentence along with the query to the model and train it to decide: Is this a good result for this query or not? But checking the whole common law, consisting of 700 million sentences, would take days to return results for each search query.
Instead, we follow a multi-step process in which we train a transformer to create representations of legal sentences in the form of vectors (essentially, a list of numbers that represents the sentence for purposes of comparison). This systems includes these three components: transformer ranker model, vector nearest neighbor index, and transformer reranker model.
We use this transformer to create vector representations of every sentence in the law and store those vectors ahead of time in a vector nearest neighbor index. When a user enters a query, we use the same transformer to create a representation of the query sentence, and then we look up its closest matches in the vector nearest neighbor index.
This transformer is based on a model that has been pre-trained on all judicial opinions, but it must be fine-tuned for the task of creating vector representations of sentences that can be fruitfully compared to each other. We train it by labeling the sentence pairs we feed the network as 1 when the sentences are similar, and 0 when they’re dissimilar, and we train the model to produce that desired output. The end result is a model that will produce vector representations of sentences that are optimized for this type of sentence comparison.
Once we have vector representations of sentences that can be compared with a distance metric, we still aren’t done. We could compare the query sentence vector to every other possible result vector, but it would still be far too slow to be commercially useful.
To speed things up further, we store the possible result vectors (one vector for each sentence in the law) in a special type of index designed for finding the nearest neighbors of a query vector, without comparing the query vector to every possible result vector. Vector nearest neighbor indices accomplish this by partitioning the possible result vectors into boxes, which contain smaller boxes, which themselves contain smaller boxes, and so on.
When a query vector is given to the index, it’s compared to a representative of the highest-level (largest) boxes. The closest box to the query vector is selected, and then the same process is repeated for the boxes within that box, and so on until a box containing only a few vectors is found. This small group is then compared to the query vector and the closest ones are taken as our results.
The lookup in the vector nearest neighbor index yields a set of results ranked by proximity to the sentence vector representing the query. These results are usually good on their own, but we found that with an additional step, we could make them even better. We fine-tuned a second transformer that can take as input both the query sentence and a result sentence and decide how good a match they are. It essentially takes the results from the prior steps and rearranges their order so that the very best results are more likely to be at the top. We call this a “re-ranker,” and we found that it substantially improved the results.
We use two different neural transformer models that are both pre-trained on the whole body of US common law and then fine-tuned to their separate tasks, one as a creator of useful sentence representations, and the other as a re-ranker that evaluates query-sentence pair matches.
To our knowledge, Casetext’s Parallel Search is the most advanced natural language semantic search tool available in the legal industry today, and our team is constantly making improvements. We invite you to try our tool, and we very much hope it helps you achieve justice for your clients. You can try it out by clicking here.
For more information about Parallel Search, reach out to contact@casetext.com.

Rapidly draft common legal letters and emails.
How this skill works
Specify the recipient, topic, and tone of the correspondence you want.
CoCounsel will produce a draft.
Chat back and forth with CoCounsel to edit the draft.
Get answers to your research questions, with explanations and supporting sources.
How this skill works
Enter a question or issue, along with relevant facts such as jurisdiction, area of law, etc.
CoCounsel will retrieve relevant legal resources and provide an answer with explanation and supporting sources.
Behind the scenes, Conduct Research generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identify the on-point case law, statutes, and regulations, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), along with the supporting sources and applicable excerpts.
Get answers to your research questions, with explanations and supporting sources.
How this skill works
Enter a question or issue, along with relevant facts such as jurisdiction, area of law, etc.
CoCounsel will retrieve relevant legal resources and provide an answer with explanation and supporting sources.
Behind the scenes, Conduct Research generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identify the on-point case law, statutes, and regulations, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), along with the supporting sources and applicable excerpts.
Get a thorough deposition outline in no time, just by describing the deponent and what’s at issue.
How this skill works
Describe the deponent and what’s at issue in the case, and CoCounsel identifies multiple highly relevant topics to address in the deposition and drafts questions for each topic.
Refine topics by including specific areas of interest and get a thorough deposition outline.
Ask questions of contracts that are analyzed in a line-by-line review
How this skill works
Allows the user to upload a set of contracts and a set of questions
This skill will provide an answer to those questions for each contract, or, if the question is not relevant to the contract, provide that information as well
Upload up to 10 contracts at once
Ask up to 10 questions of each contract
Relevant results will hyperlink to identified passages in the corresponding contract
Get a list of all parts of a set of contracts that don’t comply with a set of policies.
How this skill works
Upload a set of contracts and then describe a policy or set of policies that the contracts should comply with, e.g. "contracts must contain a right to injunctive relief, not merely the right to seek injunctive relief."
CoCounsel will review your contracts and identify any contractual clauses relevant to the policy or policies you specified.
If there is any conflict between a contractual clause and a policy you described, CoCounsel will recommend a revised clause that complies with the relevant policy. It will also identify the risks presented by a clause that does not conform to the policy you described.
Get an overview of any document in straightforward, everyday language.
How this skill works
Upload a document–e.g. a legal memorandum, judicial opinion, or contract.
CoCounsel will summarize the document using everyday terminology.
Find all instances of relevant information in a database of documents.
How this skill works
Select a database and describe what you're looking for in detail, such as templates and precedents to use as a starting point for drafting documents, or specific clauses and provisions you'd like to include in new documents you're working on.
CoCounsel identifies and delivers every instance of what you're searching for, citing sources in the database for each instance.
Behind the scenes, CoCounsel generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identifiy the on-point passages from every document in the database, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), citing applicable excerpts in specific documents.
Get a list of all parts of a set of contracts that don’t comply with a set of policies.
Ask questions of contracts that are analyzed in a line-by-line review
Get a thorough deposition outline by describing the deponent and what’s at issue.
Get answers to your research questions, with explanations and supporting sources.