Casetext currently employs artificial intelligence technology in many parts of our business, and we are continuing to deploy the latest advances as they come out of research labs. At Casetext, our guiding principle in systems design is to let humans and machines do the tasks for which they are respectively best suited. By applying this principle in practice, our backend data pipelines integrate AI-powered filtering with human expert review, and our frontend user-facing services, like CARA AI, surface the most relevant information, which our users can then digest and use in crafting arguments.
CARA AI is our flagship user-facing AI product. Discussion of its inner workings deserves its own post, but we at Casetext are also integrating AI into many more areas of our operation, and we’ll discuss a few new areas in which we’ve employed AI in the past year.
For our similar issues feature, we use a technique for turning a passage of legal text into a high-dimensional vector — a list of numbers that stands for the passage, and can be thought of as a straight line with a certain length and direction within a coordinate system. In two dimensions, vectors look like this:
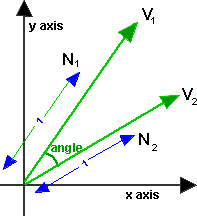
The vectors we use to represent a passage of text are in a much higher number of dimensions than two, but, in this high-dimensional space, certain mathematical techniques we use for manipulating 2-dimensional vectors still hold. Through these techniques, similar passages get similar vector representations, resulting in the angle between two similar passages’ vectors being small, and the angle between two very different passages’ vectors being large. For a given passage of text, call it Passage A, our system returns other passages from across the law whose vectors have the smallest angles with Passage A’s vector.
Citator is Casetext’s system of red flags on cases that are no longer good law. Casetext can offer an accurate citator at a much lower price than our competitors because we use AI to filter out portions of new cases that our lawyer reviewers don’t need to read. Every new case that comes out at the appeals court level or above could be overruling a prior case. Instead of having lawyers read the entirety of every case that comes out, we have our AI read the entirety of every case, and then pass along to our lawyers only the portions of a case that have a chance of overruling another case. We cast a very broad net, and show our reviewers any passage that our AI model thinks has even a tiny chance of containing overruling language. This means we sweep in many passages that are not overruling so that we can catch all of the passages that do overrule another case.
Our lawyers review each passage the model selects, determine whether it is indeed overruling another case, and then record which case has been overruled. Not only does this AI-driven approach save an enormous amount of human labor, but it also results in increased accuracy. Human reviewers who have to read entire cases looking for overruling language tend to gloss over or miss key pieces of information. Our AI algorithms, however, never tire or get bored, they read every single piece of text they are given. We have seen instances in which we have caught overruling cases that our competitors missed because, for example, the overruling language was buried in a footnote that their human reviewers must have skipped.
Our AI was trained on several thousand examples of overruling cases in which our lawyers hand-highlighted the specific language in the case that represents the overruling. Using this dataset, we trained an AI model to distinguish between overruling passages and non-overruling passages. We have humans review any passage the model tells us has even a slight chance of containing overruling language. As we have trained progressively more accurate models, we have been able to progressively reduce the number of passages our reviewers need to read without sacrificing the comprehensiveness of our citator.
Those are the applications of AI we’ve added over the past year. In the next section, I will describe the state of the most recent AI research, and the opportunities over the coming year.
We are in a very exciting time for AI in the legal industry. Until very recently, AI progress in natural language processing (NLP) lagged far behind progress in computer vision.
A major reason why computer vision exploded starting around 2012 is that the most effective type of algorithm for computer vision, the deep convolutional neural network, was amenable to transfer learning. Transfer learning is a technique in which an AI model is first pre-trained for a certain task on a large dataset and then fine-tuned for a different task on a small dataset.
Neural networks are data-hungry — where the performance of other types of models levels off as you feed them more training data, sufficiently-sized neural networks continue to improve even with vast amounts of training data. Training data, however, usually requires human hand labeling — for example, if you want to train an AI model to identify objects in images, you need to have humans look at each image and label each image with the name of the object it contains. Human hand-labeling is expensive and time-consuming. As a result, in most business situations, relatively few hand-labeled data points are available. If neural networks had to be trained from scratch on small datasets for each task, they would not have been as useful as they now are. It turned out, however, that much of the learning a neural net did on one computer vision task was also useful for other vision tasks.
Convolutional neural networks can be understood as progressively more complex pattern recognizers stacked on top of each other. The following are visualizations of the types of patterns progressive layers in a computer vision neural network recognize. This model was trained on a public dataset of over 1 million images with labels. As you can see, the first layer patterns are simple lines and gradients. The next layer are textures and basic shapes made out of combinations of the lines and gradients from the layer before, and the third is more complex shapes made from combinations of the simple shapes from the second layer.

Many shapes and textures, and certainly lines and gradients, are useful in virtually any visual recognition task. As a result, once trained on a large dataset to the point where it recognizes these types of patterns, the lower layers of a computer vision model can be repurposed for many different vision tasks. Using this technique, known as transfer learning, people with far fewer than 1 million labeled images are able to obtain excellent results on their own computer vision tasks.
Until very recently, transfer learning hasn’t been nearly as effective in natural language processing as in computer vision. Since most law-related AI tasks involve natural language processing, this has been a limitation for application of AI to law.
Some gains were made through transfer learning on pre-trained word vectors — representations of words trained on large text corpora. Word vectors were first pioneered in 2003, and were improved with an important technique called word2vec in 2013. Word2vec looked quite impressive — for example, subtracting the vector for “man” from the vector for “king”, and then adding the vector for “woman”, resulted in a vector very close to the vector for “queen”. These sorts of results showed that word vector techniques were capturing a lot of the meaning in words.
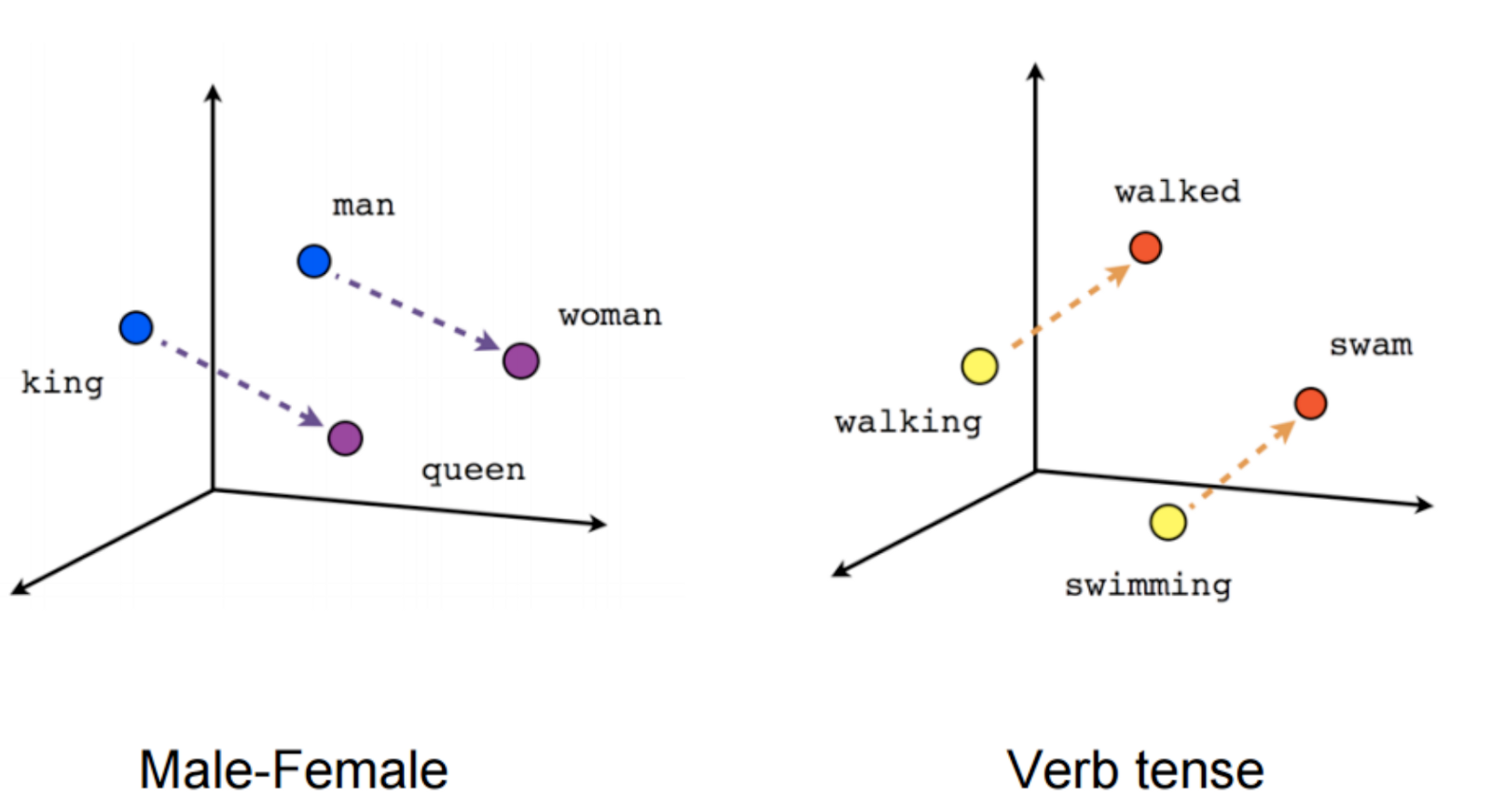
Word vectors moved the field forward, but failed to achieve the sorts of results seen with transfer learning in computer vision. Replacing words with pre-trained word vectors represents transfer learning only on the first layer of a neural network. All layers beyond the first still had to be trained from scratch, limiting the power of transfer learning in NLP.
That all changed in 2018 with the introduction of AI model architectures for natural language processing that could be used for multi-layer transfer learning. A number of components went into these model architectures based on advances in the past few years.
In 2017, a research group at Google published a paper entitled Attention is All You Need, which laid out the architecture for the neural transformer — an effective means for taking an input sequence of text and outputting a different sequence of text by paying “attention” to key parts of the input sequence when deciding each part of the output sequence. This type of architecture initially proved very useful in machine translation, but quickly expanded into other areas, because it is the best way yet known to create vectorized representations of entire sentence-length sequences of text (rather than just words, as was the case with word embeddings).
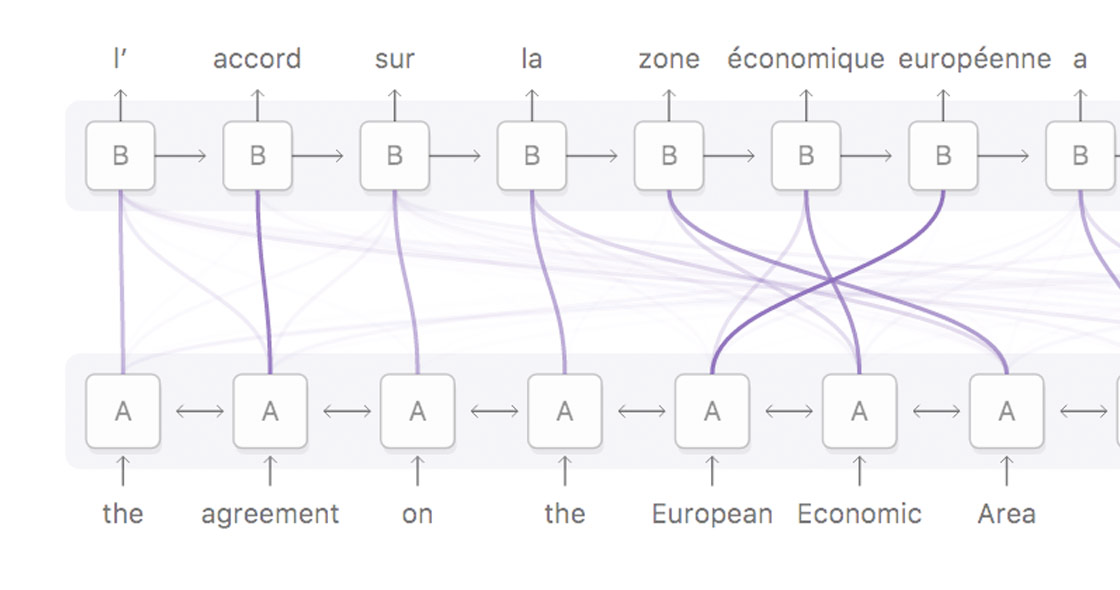
In early 2018, a group out of the Allen Institute and University of Washington introduced ELMo, a technique for creating multi-layer context-sensitive word embeddings. ELMo improved on pre-existing word embedding techniques in two ways: 1. It creates an embedding for each word in a sequence based on the word’s context, rather than creating a set single embedding for each word regardless of context. This allowed the embedding for “Will” in “Will went to the store” to be different from the embedding for “Will” in “Will you go to the concert?”. 2. ELMo word embeddings are created from many layers of a model trained to predict the next word given a sequence of text, rather than from just the first layer, leading to a more robust representation of the word.
Also in early 2018, Jeremy Howard and Sebastian Ruder introduced ULMFiT, which introduced the idea of using transfer learning on an entire model for NLP. This involved pre-training an entire model on a task not requiring human labeling (in this case, predicting the next word in a sequence of words) and then fine tuning the model on the target task.
In late 2018, all of these ideas were combined, along with a few new ideas, into various model types created by the leading NLP groups. Google released BERT in late 2018, and OpenAI released GPT-2 in early 2019. Both make use of transformers, contextual deep word embeddings, and pre-training on a task without human labeling followed by fine tuning to a specific task. Both have delivered impressive results that achieved new records across a wide range of NLP benchmarks.
Google put a new twist on pre-training without human labeling by using these two tasks, rather than the usual task of predicting the next word in a sequence:
1. In a sentence with two words removed, BERT was trained to predict what those two words were.
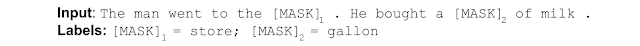
2. Given two sentences, BERT was trained to determine whether one of these sentences came after the other in a piece of text, or whether they were just two unrelated sentences.
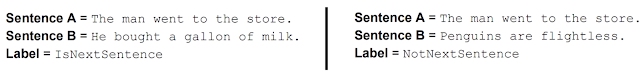
At Casetext, we have used techniques similar to BERT and GPT-2 to substantially improve our citator filtering algorithm. Incorporating these new techniques allows us to cut the percentage of passages our lawyer-reviewers need to read from 10% of passages in all new cases to just 3%. Our competitors have lawyers reading 100% of the cases that come out. This dramatic reduction in the labor hours required to produce our citator allows us to offer a citator at a much lower price than our competitors can, without sacrificing accuracy.
We will be integrating the newest techniques into many more applications in the coming months, some of which will be directly user-facing. The breakthrough that has allowed transfer learning in natural language processing will likely result in an explosion of AI applications in the legal field, and Casetext will be at the forefront in bringing them to market.

Rapidly draft common legal letters and emails.
How this skill works
Specify the recipient, topic, and tone of the correspondence you want.
CoCounsel will produce a draft.
Chat back and forth with CoCounsel to edit the draft.
Get answers to your research questions, with explanations and supporting sources.
How this skill works
Enter a question or issue, along with relevant facts such as jurisdiction, area of law, etc.
CoCounsel will retrieve relevant legal resources and provide an answer with explanation and supporting sources.
Behind the scenes, Conduct Research generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identify the on-point case law, statutes, and regulations, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), along with the supporting sources and applicable excerpts.
Get answers to your research questions, with explanations and supporting sources.
How this skill works
Enter a question or issue, along with relevant facts such as jurisdiction, area of law, etc.
CoCounsel will retrieve relevant legal resources and provide an answer with explanation and supporting sources.
Behind the scenes, Conduct Research generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identify the on-point case law, statutes, and regulations, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), along with the supporting sources and applicable excerpts.
Get a thorough deposition outline in no time, just by describing the deponent and what’s at issue.
How this skill works
Describe the deponent and what’s at issue in the case, and CoCounsel identifies multiple highly relevant topics to address in the deposition and drafts questions for each topic.
Refine topics by including specific areas of interest and get a thorough deposition outline.
Ask questions of contracts that are analyzed in a line-by-line review
How this skill works
Allows the user to upload a set of contracts and a set of questions
This skill will provide an answer to those questions for each contract, or, if the question is not relevant to the contract, provide that information as well
Upload up to 10 contracts at once
Ask up to 10 questions of each contract
Relevant results will hyperlink to identified passages in the corresponding contract
Get a list of all parts of a set of contracts that don’t comply with a set of policies.
How this skill works
Upload a set of contracts and then describe a policy or set of policies that the contracts should comply with, e.g. "contracts must contain a right to injunctive relief, not merely the right to seek injunctive relief."
CoCounsel will review your contracts and identify any contractual clauses relevant to the policy or policies you specified.
If there is any conflict between a contractual clause and a policy you described, CoCounsel will recommend a revised clause that complies with the relevant policy. It will also identify the risks presented by a clause that does not conform to the policy you described.
Get an overview of any document in straightforward, everyday language.
How this skill works
Upload a document–e.g. a legal memorandum, judicial opinion, or contract.
CoCounsel will summarize the document using everyday terminology.
Find all instances of relevant information in a database of documents.
How this skill works
Select a database and describe what you're looking for in detail, such as templates and precedents to use as a starting point for drafting documents, or specific clauses and provisions you'd like to include in new documents you're working on.
CoCounsel identifies and delivers every instance of what you're searching for, citing sources in the database for each instance.
Behind the scenes, CoCounsel generates multiple queries using keyword search, terms and connectors, boolean, and Parallel Search to identifiy the on-point passages from every document in the database, reads and analyzes the search results, and outputs a summary of its findings (i.e. an answer to the question), citing applicable excerpts in specific documents.
Get a list of all parts of a set of contracts that don’t comply with a set of policies.
Ask questions of contracts that are analyzed in a line-by-line review
Get a thorough deposition outline by describing the deponent and what’s at issue.
Get answers to your research questions, with explanations and supporting sources.